
Archive nodes - everything you need to know
Written by Alchemy
A public blockchain like Ethereum or Polygon is a global peer-to-peer network of computers. Nodes, as each peer device is known, store and process blockchain information on the blockchain and verify the network state, among other things.
While nodes can interact with other peers on the blockchain, they have different capabilities and use-cases. For example, archive nodes—discussed in this article—can store the complete historical data for the blockchain and serve it on request. These are different from full nodes that only store the recent blockchain state and light nodes that primarily request data from full nodes.
This overview covers archive nodes in detail and explains how they work in Ethereum. You’ll learn why running an archive node matters, what clients to use, and how to build your archive node to query historical blockchain data.

What is an Ethereum archive node?
An Ethereum archive node is a full node with the capacity to store the entire blockchain history, even up to the genesis block, or the first block ever created. We cover all the nodes in-depth in our guide to blockchain nodes, so here we’ll just give a quick overview of each type:
Full nodes
Full nodes store the current and most recent blockchain states (up to the last 128 blocks) and participate in validating newly added blocks. They can process transactions, execute smart contracts, and query/serve blockchain data. They can also access some historical data (via tracing) but are inefficient for this task.
Light nodes (aka “light clients”)
Light clients only store block headers, giving them access to minimal blockchain data (e.g., block timestamp, hash, mining difficulty, etc.). However, they can also interface with full nodes to get necessary data and validate information (e.g., checking transaction status or querying balances). Running a light node requires the least investment in hardware, running costs, and technical expertise.
Light Node | Full Node |
|---|---|
Block Headers | Block Headers |
Full Block State | Full Block State |
Archive nodes
Archive nodes store the same information as full nodes and all previous states of the blockchain. Running an archive node requires the most investment in hardware, running costs, technical expertise, and experience. Archive nodes build archival blockchain data quickly and efficiently, and they’re useful for querying arbitrary historical data, like a user’s balances on a specific block.
Archive nodes require more space than other nodes (since they store more data), but the investment is worth it in specific cases. In the next section, we explore how archive nodes work and how their architecture is different from other node types.
How do archive nodes work?
Archive nodes store all historical states of a blockchain between blocks. An archive node essentially contains snapshots of the network at different points in time.
What data does an archive node synchronize?
An archive node performs a “full sync”, which downloads full block data from the genesis block including block headers, transactions, and receipts.
Like all nodes, an archive node must 'synchronize' with the blockchain's current state to store and verify data on the network. Syncing requires recovering state data from peers, verifying transactions, and building a local instance of the blockchain.
Archive nodes verify all downloaded blocks, re-execute all transactions, and write all intermediate states to your disk. The last part explains why archive nodes provide an “archive” of the blockchain’s state at different moments.
How long does it take to sync an archive node?
The average estimate for syncing an archive node varies, but expect anything from one month to three months (or more if the process runs into problems).
Archive nodes take longer to sync than regular full nodes or light clients. That's simply because an archive node will recover the complete dataset for the blockchain since inception.
Full nodes and light nodes require far less time to sync, as they prune historical and unnecessary blockchain data. For example, a full node only syncs to the latest block and possibly a few hundred blocks before that block (light clients only sync the latest block headers).
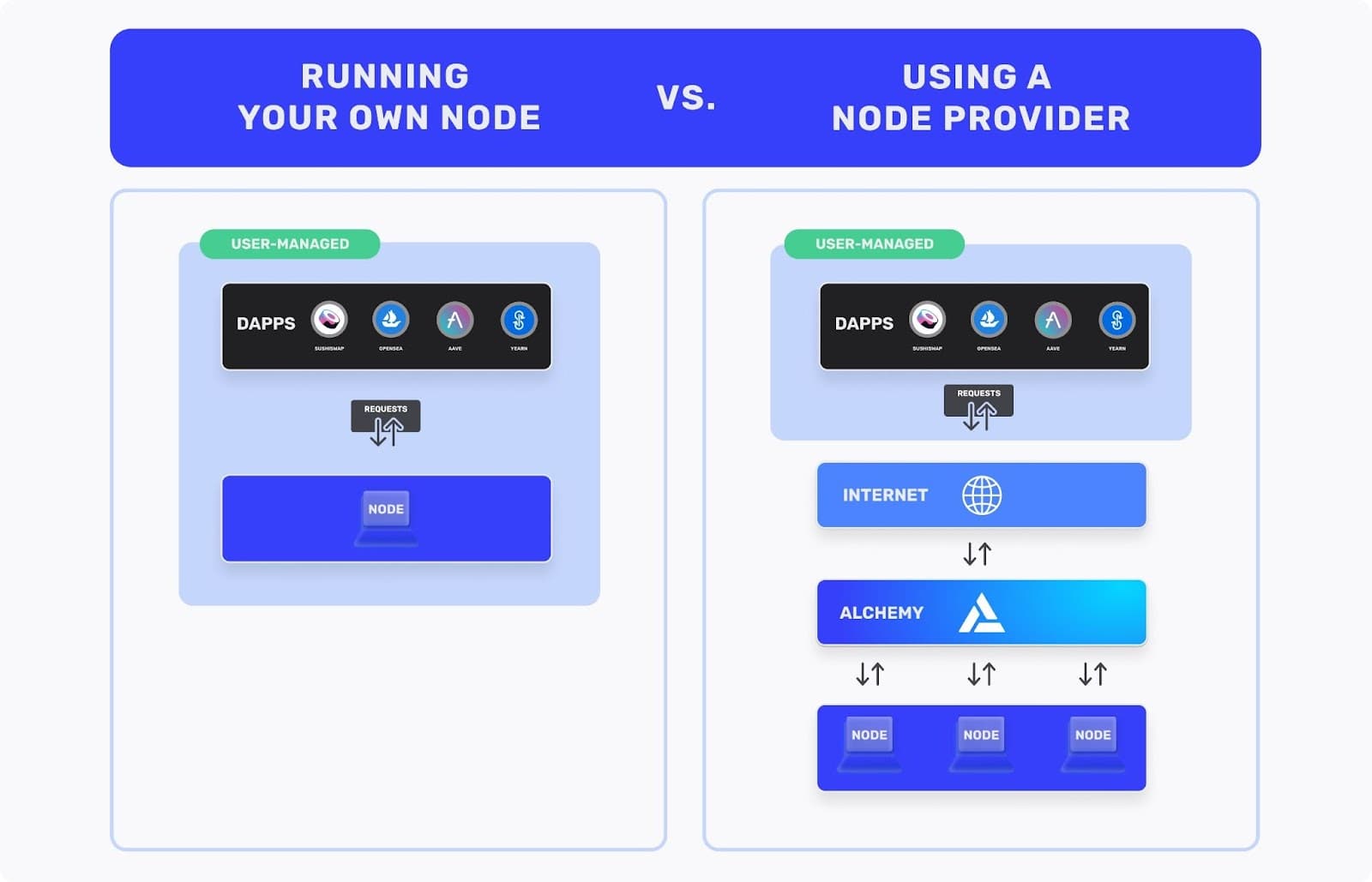
This slow rate of synchronization can stall development projects, which is why using a blockchain node provider is advisable. Node providers allow you to deploy fully-synced archive nodes on demand and save you the stress of running an archive node.
What is the size of an archive node?
As at the time of writing, archive nodes running the two major clients (Geth and OpenEthereum) store more than 10 TB of data.
For context, full nodes running Geth only store a little over 700GB of blockchain data. We’ve previously explained the reason for this disparity—namely, the need to recover blockchain data from genesis with archive nodes, unlike full nodes that regularly prune old data.

Why use archive nodes?
Archive nodes provide a gateway for accessing historical information about the blockchain. This can be useful if you need older data than those contained in the recent 128 blocks (which would be available via full nodes).
Here are two use-cases for Ethereum archive nodes:
1. Auditing historical information for blockchains
If you're building a service to audit a blockchain or gather specific pieces of historic data, an archive node is ideal. A good use-case would be if you were building a blockchain explorer (Etherscan), an on-chain analytics tool (Dune Analytics), or a cryptocurrency wallet.
These services rely on archive nodes to query and serve up old state data for users. For example, you can get information about the first block mined on Ethereum using Etherscan. Similarly, Dune Analytics can show you the total Uniswap users from inception.
2. dapp development
Running your own node is usually a minimum requirement for building a dApp. A full node is useful if you only need to do things like submitting transactions, analyzing transaction mempools, listening to smart contract events, and calling recent blockchain information.
However, calling any information beyond the first 128 blocks using a full node will throw an error. Full nodes prune blockchain data and only keep the minimal data necessary to verify the network's state.
Your dApp project needs to run an archive node to query older blockchain data quickly. The last part is important because, while you can build archival data with full nodes, it takes longer to do. With an archive node, things like getting an account's balance at a certain block number, are seamless and fast operations.
Examples of dApps that may need access to an archive node include:
- On-chain reputation services (e.g. DegenScore) that track user activity over a large period of time.
- Governance platforms (e.g., Tally, Snapshot) that allow users to discuss and vote on governance proposals.
The common thread that joins these dApp examples and others like them is the need to look at historical on-chain data.
How do you run an archive node?
Running an archive node requires a node client and beefier hardware compared to the hardware needs of full nodes or light clients.
Archive nodes are useful for retrieving historical state data without relying on third-party providers. They can put you in control of your information, especially if you need it for specific purposes (like tax compliance). But because of this massive amount of information they need to store and interact with, meeting the proper hardware requirements is a necessity.
What is an archive node client?
An archive node client is an implementation of the blockchain that you can run locally. Clients allow nodes (including archive nodes) to interact with other peers and access blockchain data. To run an Ethereum archive node without issues, you need a reliable and performant node client.
What are some popular archive node clients?
The most popular and trusted archive node clients are Go Ethereum (Geth), Erigon, Nethermind, and Besu. We can understand these clients better if we look at each of them more in-depth:
Geth archive node
Geth is one of the earliest client implementations developed for the Ethereum blockchain. It is also the main client used by Ethereum nodes. Geth boasts a large pool of tooling and features for users. It is written in Go and is publicly available under the GNU Lesser Public License. Learn more about running archive node with Geth.
Erigon archive node
Erigon is another Go-based Ethereum client for node users. Erigon provides access to efficient state storage, faster sync times, Grafana dashboard analytics, and a useful JSON-RPC daemon. Learn more about running an archive node with Erigon.
Nethermind archive node
Nethermind is an implementation of the Ethereum protocol built using the C# .NET framework. Nethermind claims to be the fastest Ethereum client available and offers stability, security, reliability, and data integrity. Learn more about running an archive node with Nethermind.
Besu archive node
Hyperledger Besu is an Ethereum client designed for enterprise users, although it can work for individuals as well. Besu is written in Java and offers useful features, including tracing, GraphQL API, and extensive monitoring. Learn more about running an archive node with Besu.
What hardware do you need to run an archive node?
Because archive nodes perform more read-write operations and use more RAM and CPU than other types of nodes, they may demand investing in specialized hardware to compensate for their computation-heavy duties.
Below is a list of requirements for running an Ethereum archive node:
Operating system: Windows, Linux, or macOS
Processor: Intel i7 or equivalent
Storage: Solid State Drive (SSD) with at least 8-10 TB of space
RAM: RAM disk with at least 16-32GB
CPU: CPU with 4+ cores
Bandwidth: Speeds of 25+ MB/s
Once you set up your node hardware and configure the client, you can start with the Ethereum blockchain using frontend libraries (ethers.js/web3.js) and JSON-RPC calls. For example, you can try to get the balance for an old address by calling the `eth_getBalance` function.
Free archive node access on Alchemy
As we’ve explained, running an Ethereum archive node requires a huge investment. This doesn’t take into account the time and energy you need to manage the archive node itself, especially if it goes out of sync. But you can skip on all of that by connecting to an archive node endpoint managed by a node provider, like Alchemy.
Alchemy's Supernode supports unlimited requests for archive data and provides access to all the historical blockchain information you need. The good part? You can connect to an archive node for free.
Alchemy offers unrestricted archive node access even for users on Supernode’s free tier. This means you can get past on-chain data and even fork the entire chain from genesis, without paying additional fees. Alchemy includes access to archive nodes for Polygon, Ethereum, and many other popular chains.
How to connect to full archive nodes on Alchemy?
Here is a step-by-step process for connecting to archive nodes with Alchemy:
-
Sign up for an account (it's free!) and create your first project.
-
Create your Alchemy key. This is the URL endpoint for connecting to your archive node.
-
Start sending requests from the command-line interface to the Ethereum blockchain for archival data.
Conclusion
Archive nodes can store past blockchain states extending beyond the most recent 128 blocks. If your dApp or Web3 service requires accessing historical blockchain data, running an archive node is a no-brainer. But be aware that the demands of running a fully functional archive node can discourage developers and stall development plans.
Alchemy’s Supernode solves this problem by connecting users with archive nodes that use free URL endpoints. With Alchemy, running an Ethereum archive node has never been easier!
Related Overviews




Build blockchain magic
Alchemy combines the most powerful web3 developer products and tools with resources, community and legendary support.